It was good to moderate a discussion on bridging the gap between strategy and execution. Great, candid conversation and plenty I’ll take back to the office.
Key takeaways:
☑️ Buy-in happens when you translate risk into business impact, work across functions and deliver early, visible wins.
☑️ Common pitfall: a glossy PowerPoint deck with no delivery plan. Convert vision into smaller, time-boxed outcomes with clear owners.
☑️ What makes the difference: realistic roadmaps, measurable OKRs (outcomes not activity), empowered teams and a steady governance cadence that removes blockers.
Thanks to the panelists and everyone in the audience who challenged orthodoxies – I learned as much as I hope I gave.
Thank you to everyone who stopped by the book signing. It was a pleasure to meet readers and hear your thoughts. If you missed it, you can still get the book on Amazon: https://a.co/d/0fai5zyh
Security failures are rarely a technology problem alone. They’re socio-technical failures: mismatches between how controls are designed and how people actually work under pressure. If you want resilient organisations, start by redesigning security so it fits human cognition, incentives and workflows. Then measure and improve it.
Think like a behavioural engineer
Apply simple behavioural-science tools to reduce errors and increase adoption:
Defaults beat persuasion. Make the secure choice the path of least resistance: automatic updates, default multi-factor authentication, managed device profiles, single sign-on with conditional access. Defaults change behaviour at scale without relying on willpower.
Reduce friction where it matters. Map high-risk workflows (sales demos, incident response, customer support) and remove unnecessary steps that push people toward risky workarounds (like using unapproved software). Where friction is unavoidable, provide fast, well-documented alternatives.
Nudge, don’t nag. Use contextual micro-prompts (like in-app reminders) at the moment of decision rather than one-off training. Framing matters: emphasise how a control helps the person do their job, not just what it prevents.
Commitment and incentives. Encourage teams to publicly adopt small security commitments (e.g. “we report suspicious emails”) and recognise them. Social proof is powerful – people emulate peers more than policies.
Build trust, not fear
A reporting culture requires psychological safety.
Adopt blameless post-incident reviews for honest mistakes; separate malice investigations from learning reviews.
Be transparent: explain why rules exist, how they are enforced and what happens after a report.
Lead by example: executives and managers must follow the rules visibly. Norms are set from the top.
Practical programme components
Security champion network. One trained representative per team. Responsibilities: localising guidance, triaging near-misses and feeding back usability problems to the security team.
Lightweight feedback loops. Short surveys, near-miss logs and regular champion roundtables to capture usability issues and unearth workarounds.
Measure what matters. Track metrics tied to risk and behaviour.
Metrics that inform action (not vanity)
Stop counting clicks and start tracking signals that show cultural change and risk reduction:
Reporting latency: median time from detection to report. Increasing latency can indicate reduced psychological safety (fear of blame), friction in the reporting path (hard-to-find button) or gaps in frontline detection capability. A drop in latency after a campaign usually signals improved awareness or lowered friction.
Always interpret in context: rising near-miss reports with falling latency can be positive (visibility improving). Review volume and type alongside latency before deciding.
Inquiries rate: median number of proactive security inquiries (help requests, pre-deployment checks, risk questions). An increase usually signals growing trust and willingness to engage with security; a sustained fall may indicate rising friction, unresponsiveness or fear.
If rate rises sharply with no matching incident reduction, validate whether confusion is driving questions (update docs) or whether new features need security approvals (streamline process).
Confidence and impact: employees’ reported confidence to perform required security tasks (backups, secure file sharing, suspicious email reporting) and their belief that those actions produce practical organisational outcomes (risk reduction, follow-up action, leadership support).
An increase may signal stronger capability and perceived efficacy of security actions. While a decrease indicates skills gaps, tooling or access friction or perception that actions don’t lead to change.
Metrics should prompt decisions (e.g., simplify guidance if dwell time on key security pages is low, fund an automated patching project if mean time to remediate is unacceptable), not decorate slide decks.
Experiment, measure, repeat
Treat culture change like product development: hypothesis → experiment → measure → adjust. Run small pilots (one business unit, one workflow), measure impact on behaviour and operational outcomes, then scale the successful patterns.
Things you can try this month
Map 3 high-risk workflows and design safer fast paths.
Stand up a security champion pilot in two teams.
Change one reporting process to be blameless and measure reporting latency.
Implement or verify secure defaults for identity and patching.
Define 3 meaningful metrics and publish baseline values.
When security becomes the way people naturally work, supported by defaults, fast safe paths and a culture that rewards reporting and improvement, it stops being an obstacle and becomes an enabler. That’s the real return on investment: fewer crises, faster recovery and the confidence to innovate securely.
If you’d like to learn more, check out the second edition of The Psychology of Information Security for more practical guidance on building a positive security culture.
As AI adoption accelerates, leaders face the challenge of setting clear boundaries, not only around what AI should and shouldn’t do, but also around who holds responsibility for its oversight.
It was great to share my thoughts and answer audience questions during this panel discussion.
Governance must be cross-functional: security, risk, data and the business share accountability. I also reinforced the importance of guardrails, particularly forAgentic AI: automate low-risk work, but keep humans in the loop for decisions that affect safety, rights or reputation. Classify models and agents by impact and apply controls accordingly.
As organisations accelerate AI adoption, a familiar pattern is emerging: security teams – often the CISO – are increasingly asked to own or coordinate AI governance. That outcome is not an accident. Security leaders already operate across departmental boundaries, manage data inventories, run cross-functional programs and are trusted by executives and boards to solve hard, systemic problems. AI initiatives are inherently cross-disciplinary, data-centric and integrated into product and vendor ecosystems, so responsibility naturally flows toward teams that already do that work. This operational reality creates an opportunity: security can (and should) move from firefighting to shaping safe adoption practices that preserve value and reduce harm.
In this blog I outline key strategies on how to be successfully in leading AI governance initiatives in your organisation.
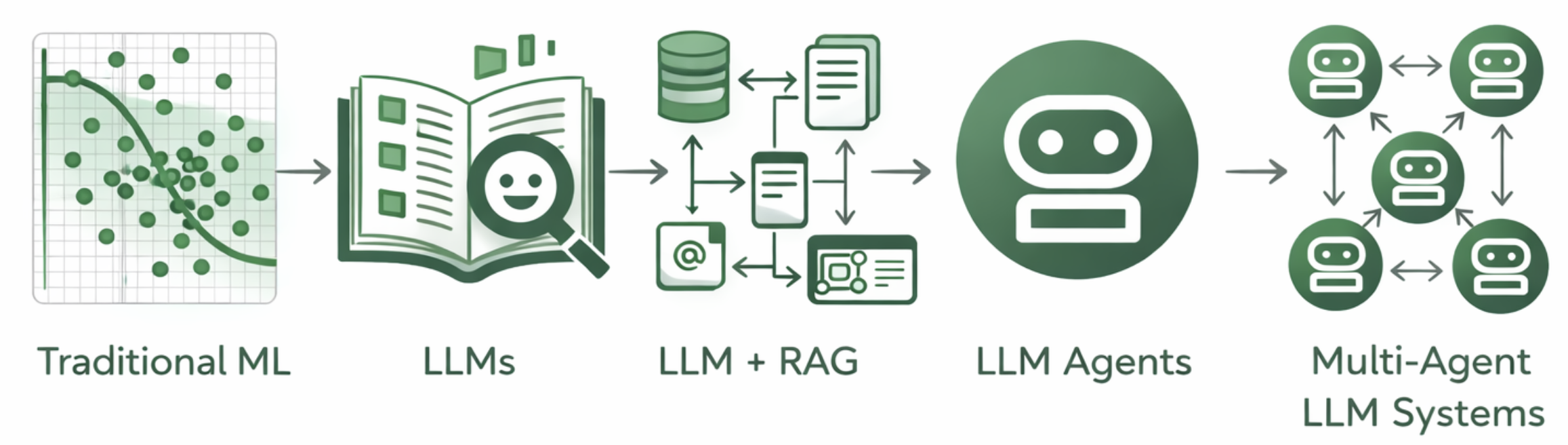
We are entering the agentic era – an inflection point defined by AI systems that can reason, plan and take action autonomously. This shift may be among the most consequential technological transformations of our generation, and it carries an equally significant obligation: to ensure these systems are designed, governed and deployed in ways that earn and sustain trust.
I completed a 5-Day AI Agents Intensive Course where we dove deep in Google’s open source Agent Development Toolkit. In this blog, I’ll share key takeaways and practical suggestions so you can navigate this shift and learn to build AI agents of your own.
I recently qualified as surf lifesaver. Starting up as less than a confident ocean swimmer, this 8-week Bronze Medallion course definitely pushed me out of my comfort zone! I learned rescue techniques, first aid, resuscitation and how to operate in rough conditions.
Some lessons I learned apply to leadership and cyber security: practice beats theory, situational awareness matters, clear communication saves time (and sometimes lives) and simple tools often outperform complexity. Most of all, the course reinforced humility – competence grows through steady practice and teamwork.
Grateful for the experience and the reminder that fundamentals matter in any high-risk role. Stay safe!
I’m finishing the year having completed The Observership Program as a Board Observer with the Lokahi Foundation, an experience that provided valuable insight into board governance.
Alongside social impact and governance training from the Australian Institute of Company Directors, tailored to not-for-profit board directors, I spent twelve months observing a purpose-driven board and deepening my understanding of how decisions that matter are made.
Top takeaways:
• The art of questioning – how different types of questions shape discussion and drive clarity.
• Director responsibilities – the difference between reporting to a board and serving on one.
• Bringing stakeholders on a journey – effective communication, buy-in and sustained impact.
• Practical exposure to fundraising, strategy, marketing, sustainability and operations in the not-for-profit sector.
I had a chance to apply skills from my MBA and global corporate experience to support the board. I also drew on my domain expertise in cybersecurity, data protection, technology innovation, AI and impact measurement, particularly championing ethical data practices.
Thank you to the Lokahi Foundation board and the Observership Program for the opportunity to learn and give back. I’m excited to keep building these skills and to support future boardrooms.
I recently took the stage to talk about one of the most consequential inflection points facing FinTech: the rapid arrival of agentic AI – systems that plan, decide and act autonomously – and what it means for risk, reputation, regulation and customer trust. Below is a distillation of the talk: what agentic AI actually is, why FinTechs are racing to adopt it, the real cyber threats it brings, and a pragmatic playbook leaders can use today.