As AI adoption accelerates, leaders face the challenge of setting clear boundaries, not only around what AI should and shouldn’t do, but also around who holds responsibility for its oversight.
It was great to share my thoughts and answer audience questions during this panel discussion.
Governance must be cross-functional: security, risk, data and the business share accountability. I also reinforced the importance of guardrails, particularly forAgentic AI: automate low-risk work, but keep humans in the loop for decisions that affect safety, rights or reputation. Classify models and agents by impact and apply controls accordingly.
I’m proud to share that I’ve completed SANS’s LDR553: Cyber Incident Management hands-on training and earned the GIAC Cyber Incident Leader (GCIL) certification.
This course sharpened my ability to guide teams through every stage of a breach. I was awarded a challenge coin for the top score in the final capstone project.
During the session, Richard broke down risk quantification, focusing on identifying the risks most likely to cause significant business losses where assets, threats and vulnerabilities intersect.
I’m also glad to receive his book for correctly estimating cost in our the discussions. It’s one of the most influential books in security: it challenges subjective risk assessments, offering practical frameworks for using data, probability and economics to drive smarter security decisions.
Cyber security is a relentless race to keep pace with evolving threats, where staying ahead isn’t always possible. Advancing cyber maturity demands more than just reactive measures—it requires proactive strategies, cultural alignment, and a deep understanding of emerging risks.
I had an opportunity to share my thoughts on staying informed about threats, defining cyber maturity, and aligning security metrics with business goals with Corinium’s Maddie Abe ahead of my appearance as a speaker at the upcoming CISO Sydney next month.
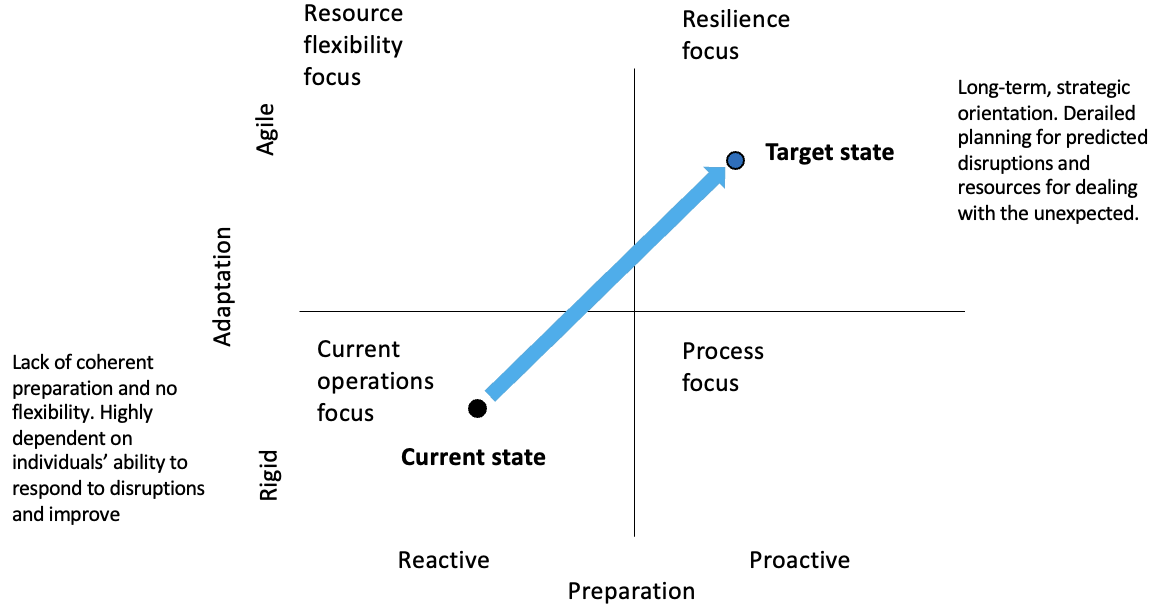
Resilience matrix, adapted from Burnard, Bhamra & Tsinopoulos (2018, p. 357).
Scenario analysis is a powerful tool to enhance strategic thinking and strategic responses. It aims to examine how our environment might play out in the future and can help organisations ask the right questions, reduce biases and prepare for the unexpected.
What are scenarios? Simply put, these are short explanatory stories with an attention- grabbing and easy-to-remember title. They define plausible futures and often based on trends and uncertainties.
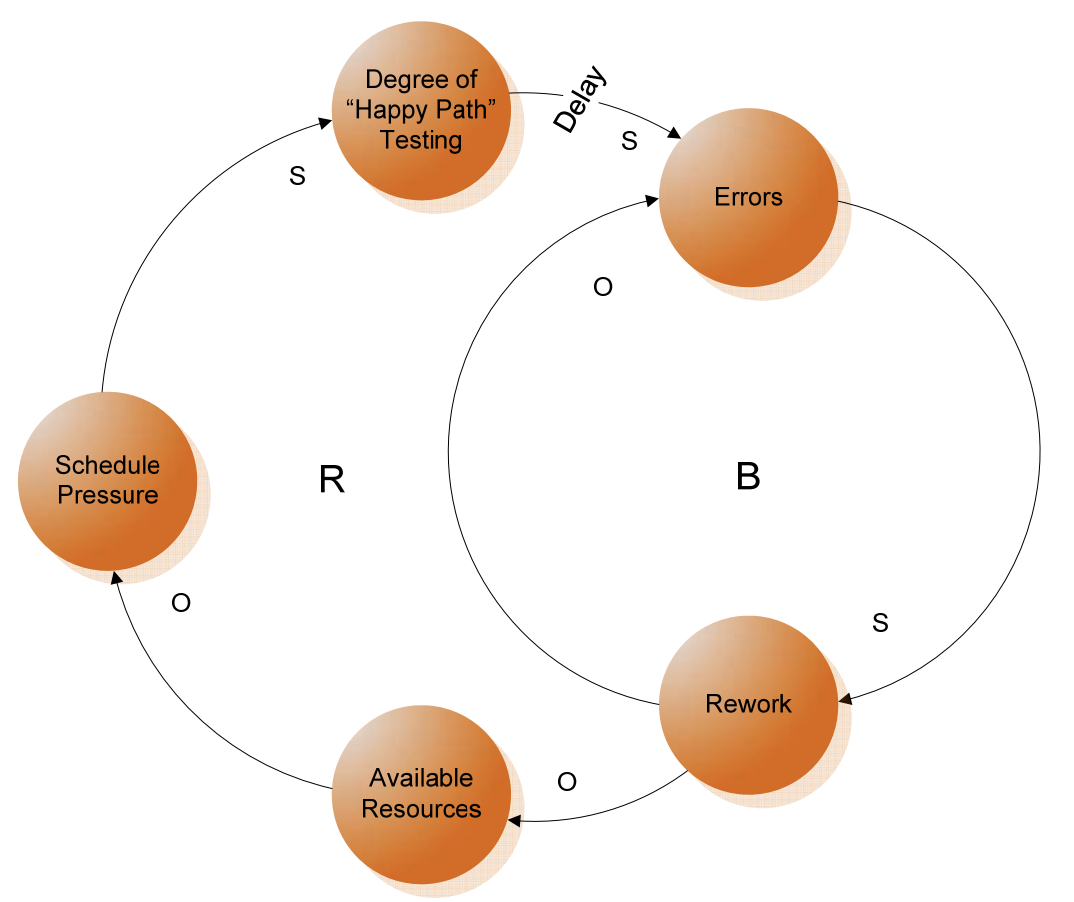
A Causal Loop Diagram of The Happy Path Testing Pattern, Acquisition Archetypes, Carnegie Mellon University
Product security is more than running code scanning tools and facilitating pentests. Yet that’s what many security teams focus on. Secure coding is not a standalone discipline, it’s about developing systems that are safe. It starts with organisational culture, embedding the right behaviours and building on existing code quality practices.
In the DevSecOps paradigm, the need for manual testing and review is minimised in favour of speed and agility. Security input should be provided as early as possible, and at every stage of the process. Automation, therefore, becomes key. Responsibility for quality and security as well as decision-making power should also shift to the local teams delivering working software. Appropriate security training must be provided to these teams to reduce the reliance on dedicated security resources.
I created a diagram illustrating a simplified software development lifecycle to show where security-enhancing practices, input and tests are useful. The process should be understood as a continuous cycle but is represented in a straight line for the ease of reading.
There will, of course, be variations in this process – the one used in your organisation might be different. The principles presented here, however, can be applied to any development lifecycle, your specific pipeline and tooling.
I deliberately kept this representation tool and vendor agnostic. For some example tools and techniques at every stage, feel free to check out the DevSecOps tag on this site.
Bug bounty programmes are becoming the norm in larger software organisations but it doesn’t mean you have to be Google or Facebook to run one for continuous security testing and engaging with the security community..
Setting it up can be easier than you might think as there are multiple platforms like HackerOne, BugCrowd or similar out there that can help with centralised management. They also offer an option to introduce it gradually through private participation first before opening it to the whole world.
At a minimum, you can have a dedicated email address (e.g. security@yourexamplecompanyname) that security researchers can use to report security issues. Having a page transparently explaining the participation terms, scope and payout rate also helps. Additionally, it’s good to have appropriate tooling to track issues and verify fixes.
Even if you don’t have any of the above, security researchers can still find vulnerabilities in your product and report them to you responsibly, so you effectively get free testing but can exercise limited control over it. Therefore, it’s a good idea to have a process in place to keep them happy enough to avoid them disclosing issues publicly.
There is probably nothing more frustrating for a security researcher than receiving no response (apart perhaps from being threatened legal action), so communication is key. At the very least, thank them and request more information to help verify their finding while you kick off the investigation internally. Bonus points for keeping them in the loop when it comes to plans for remediation, if appropriate.
There are some prerequisites for setting up the bug bounty programme though. Beyond the obvious budget requirement for paying researchers for the vulnerabilities they discover, there is a broader need for engineering resources being available to analyse reported issues and work on improving the security of your products and services. What’s the point of setting up a bug bounty programme if no one is looking at the findings?
Many companies, therefore, might feel they are not ready for a bug bounty programme. They may have too many known issues already and fear they will be overwhelmed with duplicate submissions. These might indeed be problematic to manage, so such organisations are better off focusing their efforts on remediating known vulnerabilities and implementing measures to prevent them (e.g. setting up a Content Security Policy).
They could also consider introducing security tests in the pipeline as this will help catch potential vulnerabilities much earlier in the process, so the bug bounty programme can be used as a fall back mechanism, not the primary way for identifying security issues.
Using abstractions to think about risks is a useful technique to identify the ways an attacker could compromise a system.
There are various approaches to perform threat modelling but at the core, it’s about understanding what we are building, what can go wrong with it and what we should do about it.
Here is a good video by SAFECode introducing the concept: