I bet you already know that you should set up CloudTrail in your AWS accounts, if you haven’t already. This service captures all the API activity taking place in your AWS account and stores it in an S3 bucket for that account by default. This means you would have to configure the logging and storage permissions for every AWS account your company has. If you are tasked with securing your cloud infrastructure, you will first need to establish how many accounts your organisation owns and how CloudTrail is configured for them. Additionally, you would want to have access to S3 buckets storing these logs in every account to be able to analyse them.
If this doesn’t sound complicated already, think of a potential error in permissions where logs can be deleted by an account administrator. Or situations where new accounts are created without your awareness and therefore not part of the overall logging pipeline. Luckily, these scenarios can be avoided if you are using the Organization Trail.
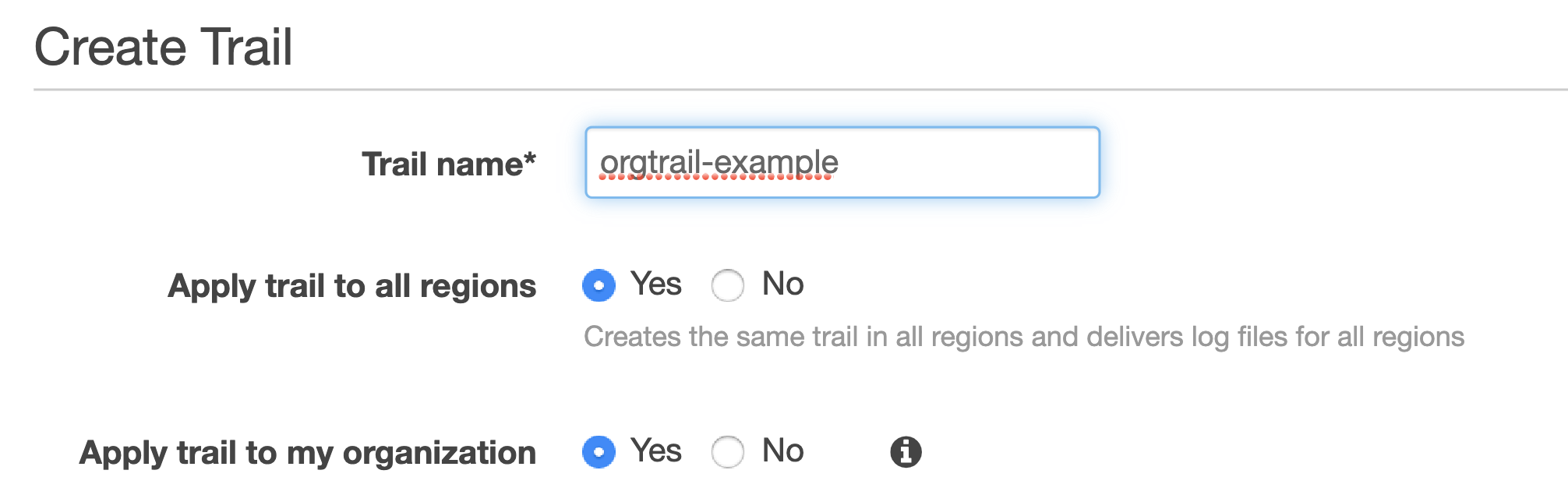
Your accounts have to be part of the same AWS Organization, of course. You would also need to have a separate account for security operations. Hopefully, this has been done already. If not, feel free to refer to my previous blogs on inventorying your assets and IAM fundamentals for further guidance on setting it up.
Establishing an Organization Trail not only allows you to collect, store and analyse logs centrally, it also ensures all new accounts created will have CloudTrail enabled and configured by default (and it cannot be turned off by child accounts).

Switch on Insights while you’re at it. This will simply the analysis down the line, alerting unusual API activity. Logging data events (for both S3 and Lambda) and integrating with CloudWatch Logs is also a good idea.
Where can all these logs be stored? The best destination (before archiving) is the S3 bucket in your account used for security operations, so that’s where it should be created.
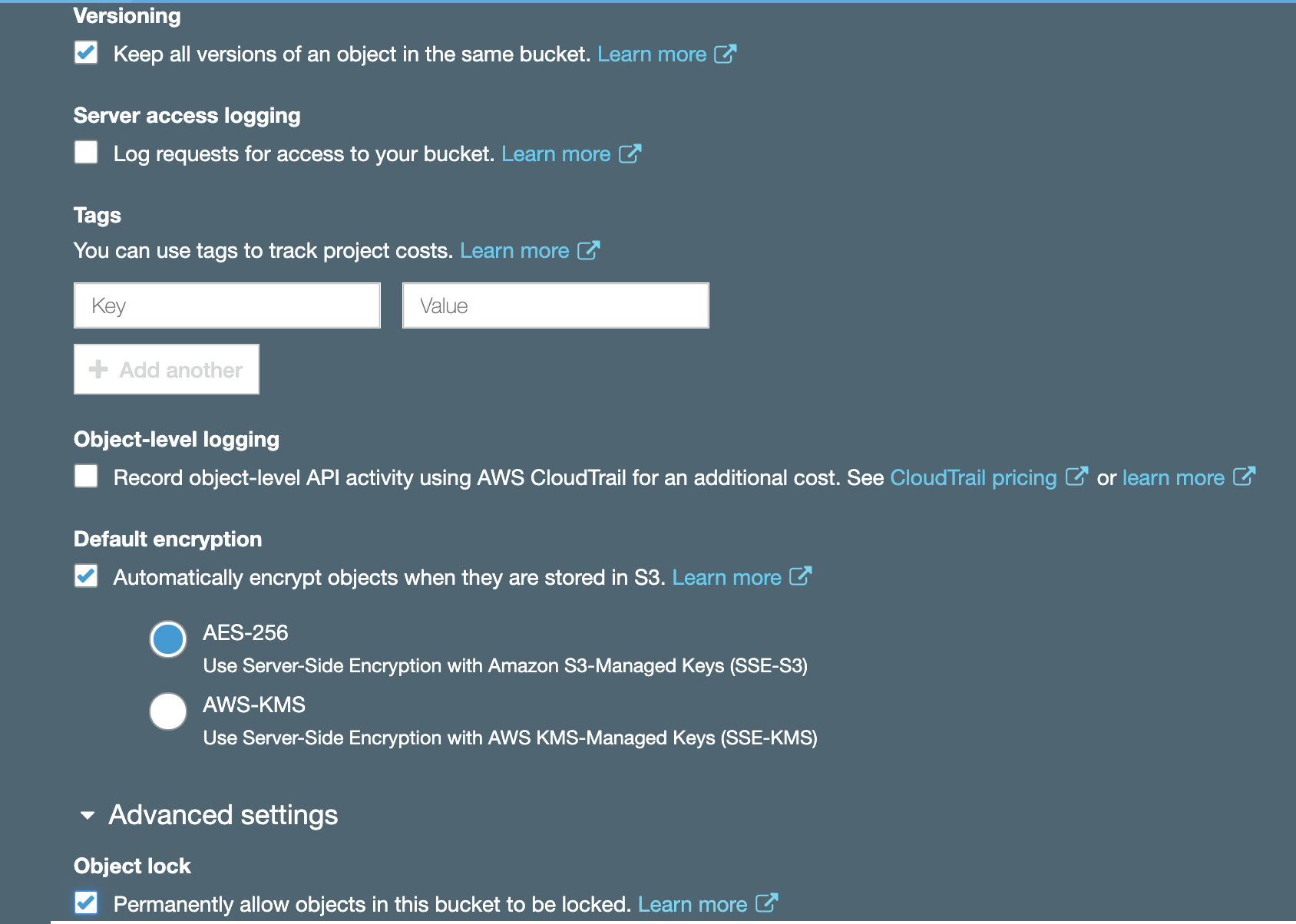
Enabling encryption and Object Lock is always a good idea. While encryption will help with confidentiality of your log data, Object Lock will ensure redundancy and prevent objects from accidental deletion. It requires versioning to be enabled and is best configured on bucket creation. Don’t forget to block public access!
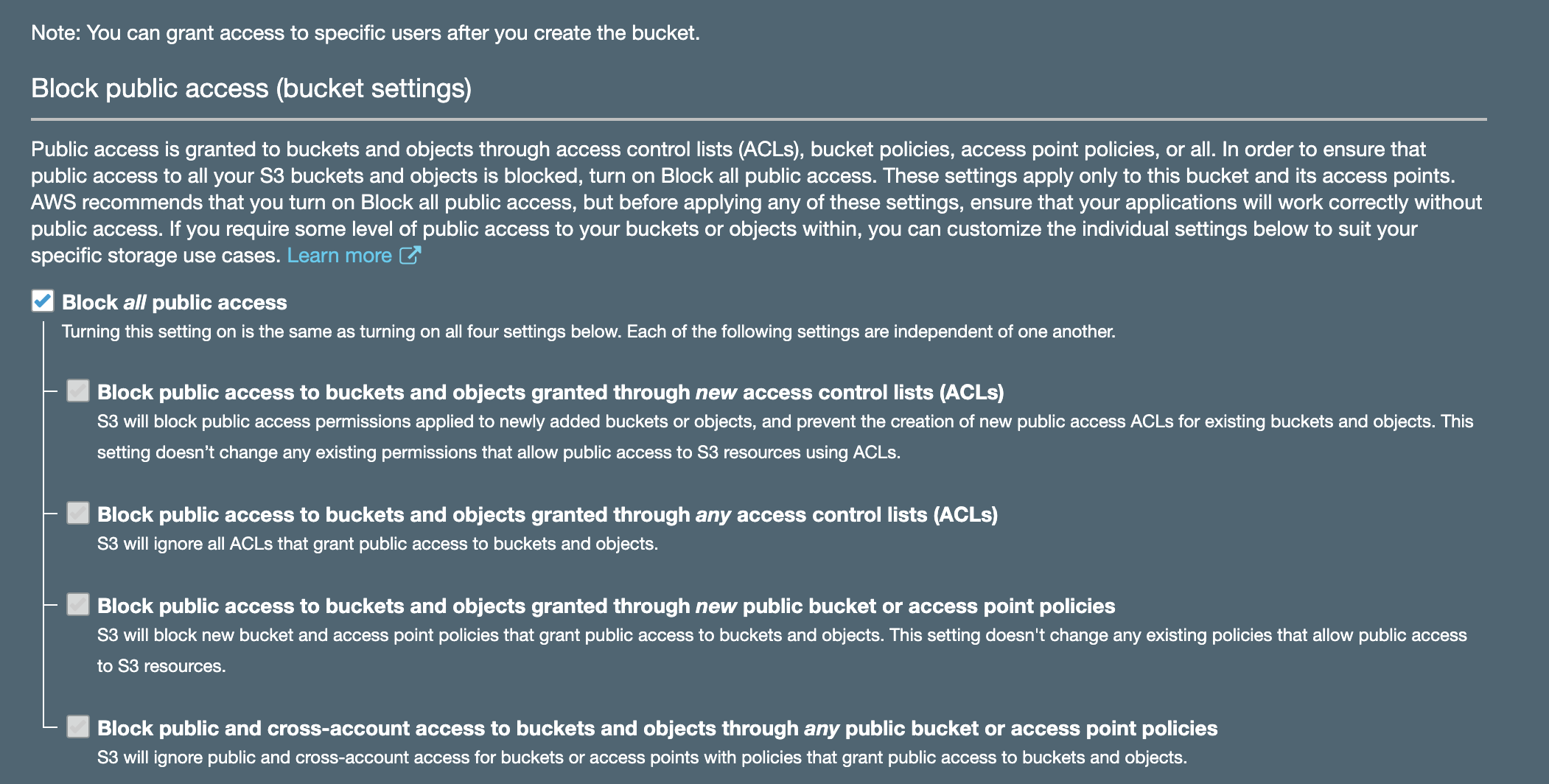
You must then use your organisational root account to set up Organization Trail, selecting the bucket you created in your operational security account as a destination (rather than creating a new bucket in your master account).
For this to work, you will need to set up appropriate permissions on that bucket. It is also advisable to set up access for child accounts to be able to read their own logs.
If you had other trails in your accounts previously, feel free to turn them off to avoid unnecessary duplication and save money. It’s best to give it a day for these trails to run in parallel though to ensure nothing is lost in transition. Keep your old S3 buckets used for collection in your accounts previously; you will need these logs too. You can configure lifecycle policies and perhaps transfer them to Glacier to save on storage costs later.
And that’s how you set up CloudTrail for centralised collection, storage and analysis.

2 Comments