I wrote previously about inventorying your assets in AWS using an external open source tool. An alternative to this approach is to use AWS Config.
This AWS service certainly has its imperfections (e.g. it doesn’t support all AWS resources) but it is easy to set up and can be quite useful too. When you first enable it, Config will analyse the resources in your account and make the summary available to you in a dashboard (example below). It’s a regional service, so you might want to enable it in all active regions.
Config, however, doesn’t stop there. You can now use this snapshot as a reference point and track all changes to your resources on a timeline. It can be useful when you need to analyse historical records, demonstrate compliance or gain visibility in your change management practices. It can also notify you of any configuration changes if you set up SNS notifications.
Config rules allow you to continuously track compliance with various baselines. AWS provide quite a few out of the box and you can create your own to tailor to the specific environment you operate in. You have to pay separately for rules, so I encourage you to check out pricing first.
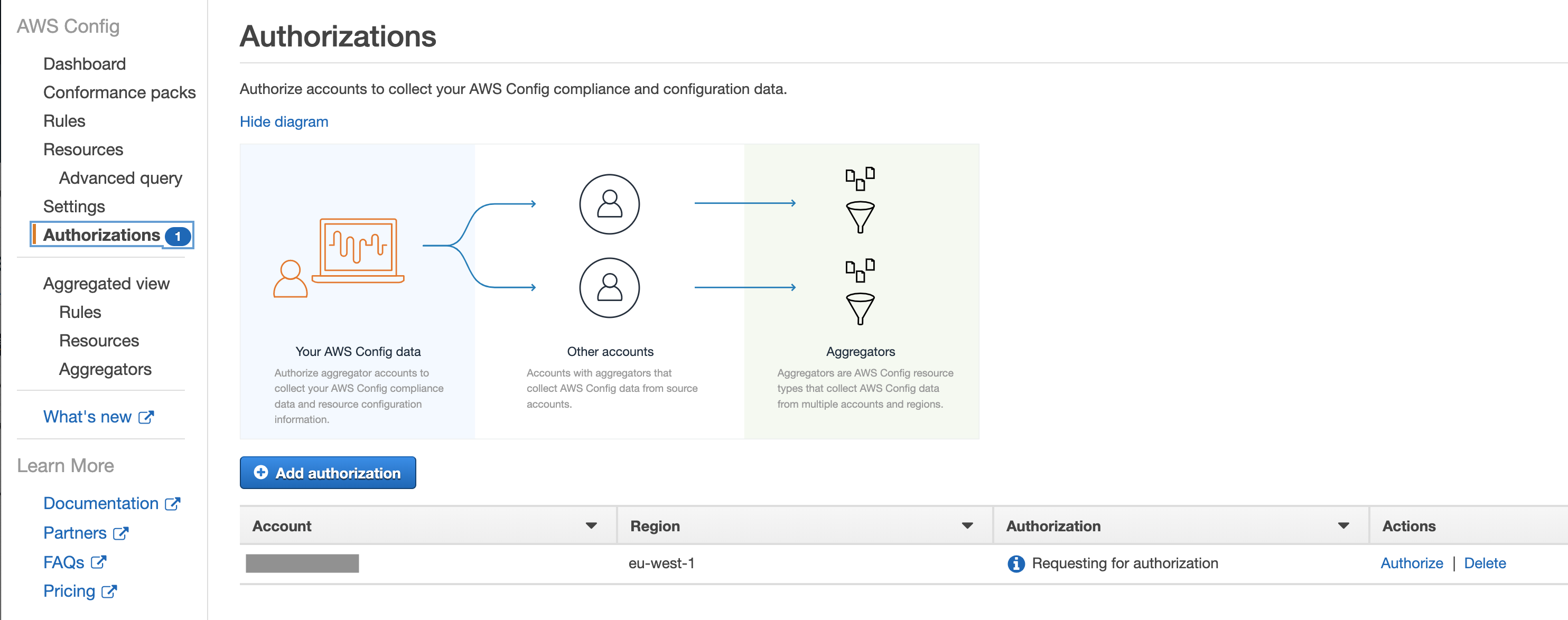
As with some other AWS services, you can aggregate the data in a single account. I recommend using the account used for security operations as a master. You will then need to establish a two-way handshake, inviting member accounts and authorising the master account to be able to consolidate the results.
There are several ways to implement threat detection in AWS but by far the easiest (and perhaps cheapest) set up is to use Amazon’s native GuardDuty. It detects root user logins, policy changes, compromised keys, instances, users and more. As an added benefit, Amazon keep adding new rules as they continue evolving the service.
To detect threats in your AWS environment, GuardDuty ingests CloudTrail, VPC FlowLogs and VPC DNS logs. You don’t need to configure these separately for GuardDuty to be able to access them, simplifying the set up. The price of the service depends on the number of events analysed but it comes with a free 30-day trial which allows you to understand the scope, utility and potential costs.
It’s a regional service, so it should be enabled in all regions, even the ones you currently don’t have any resources. You might start using new regions in the future and, perhaps more importantly, the attackers might do it on your behalf. It doesn’t cost extra in the region with no activity, so there is really no excuse to switch it on everywhere.
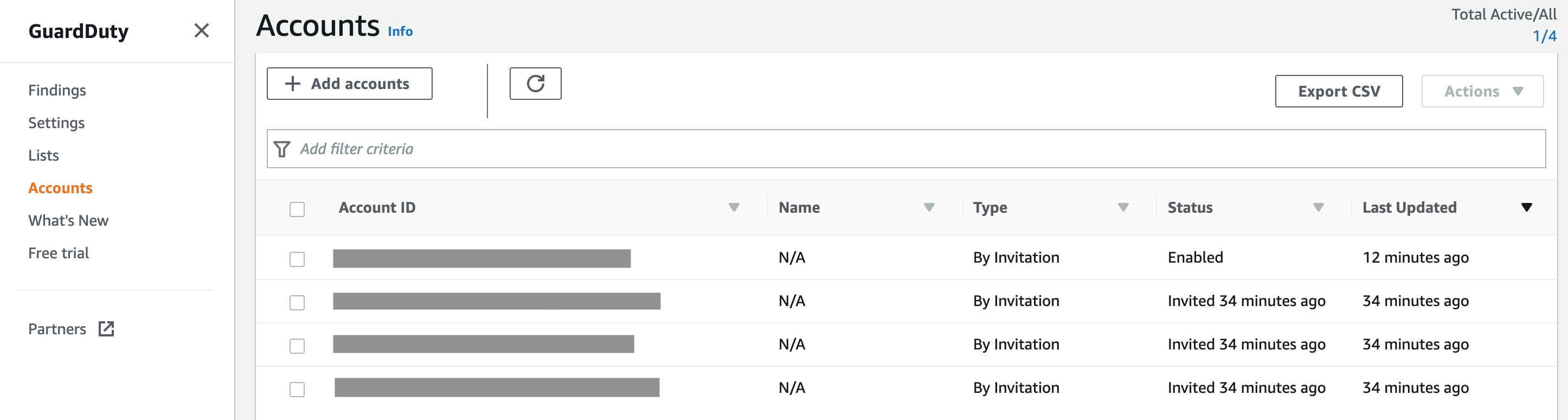
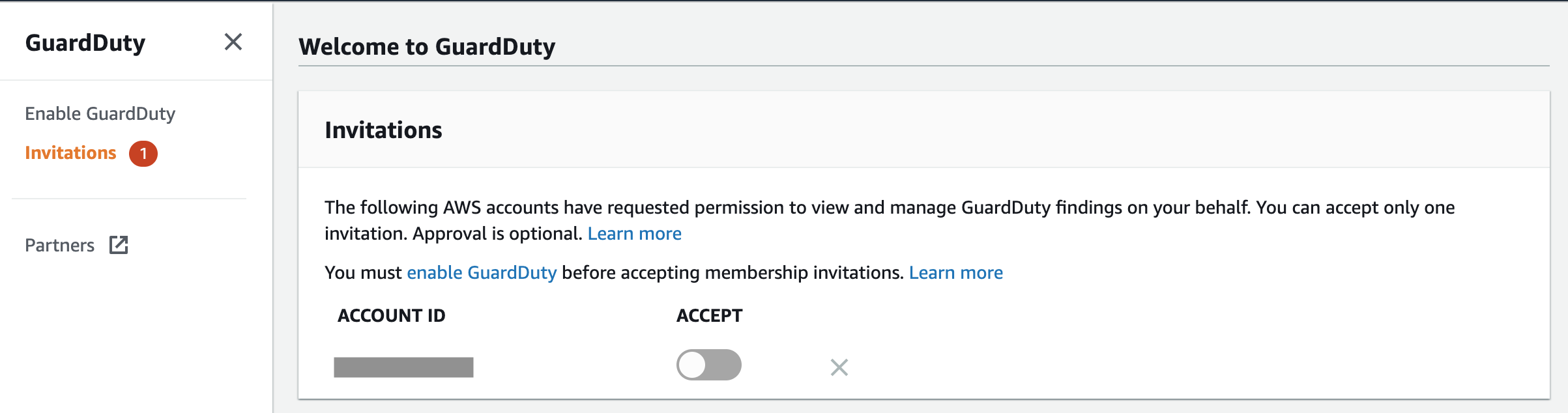
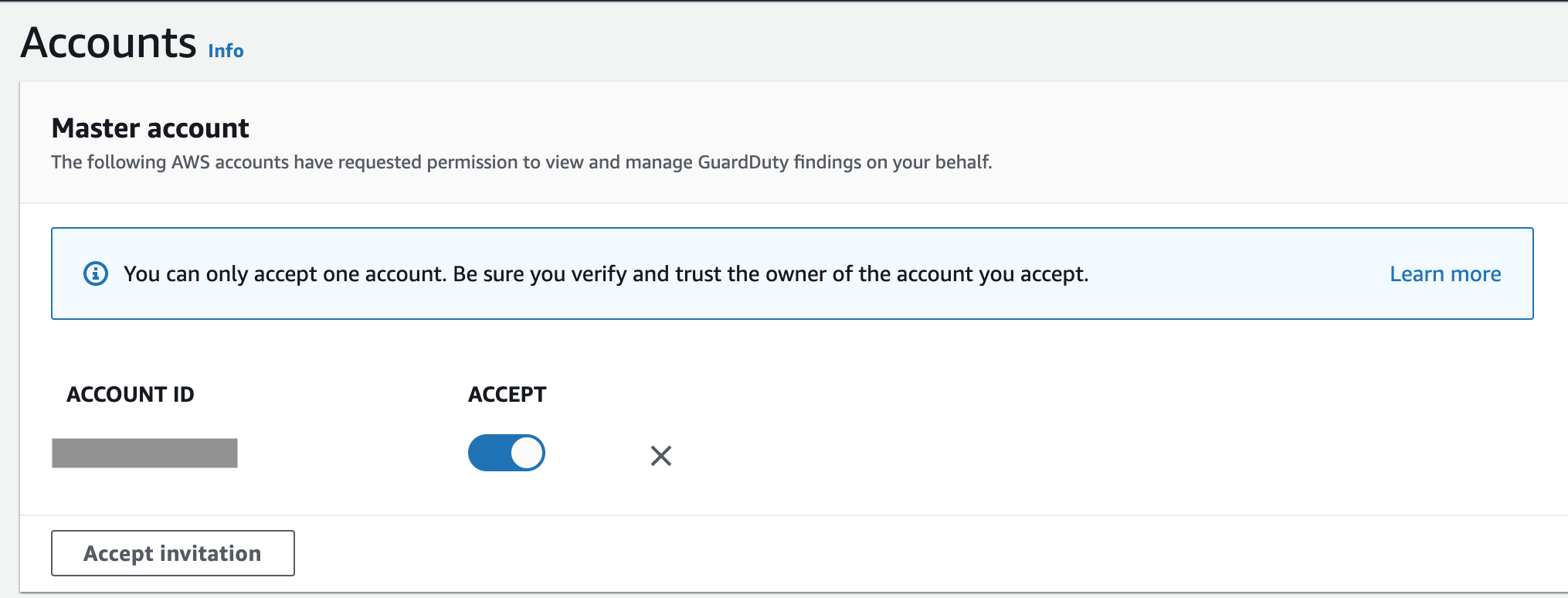
To streamline the management, I recommend following the AWS guidance on channelling the findings to a single account, where they can be analysed by the security operations team.
It requires establishing master-member relationship between accounts, where the master account will be the one monitored by the security operations team. You will then need to enable GuardDuty in every member account and accept the invite from the master.
You don’t have to rely on the AWS console to access GuardDuty findings, as they can be streamed using CloudWatch Events and Kinesis to centralise the analysis. You can also write custom rules specific to your environment and mute existing ones customising the implementation. These, however, require a bit more practice, so I will cover them in future blogs.
Committing passwords, SSH keys and API keys to your code repositories is quite common. This doesn’t make it less dangerous. Yes, if you are ‘moving fast and breaking things’, it is sometimes easier to take shortcuts to simplify development and testing. But these broken things will eventually have to be fixed, as security of your product and perhaps even company, is at risk. Fixing things later in the development cycle is likely be more complicated and costly.
I’m not trying to scaremonger, there are already plenty of news articles about data breaches wiping out value for companies. My point is merely about the fact that it is much easier to address things early in the development, rather than waiting for a pentest or, worse still, a malicious attacker to discover these vulnerabilities.
Disciplined engineering and teaching your staff secure software development are certainly great ways to tackle this. There has to, however, be a fallback mechanism to detect (and prevent) mistakes. Thankfully, there are a number of open-source tools that can help you with that:
You will have to assess your own environment to pick the right tool that suits your organisation best.
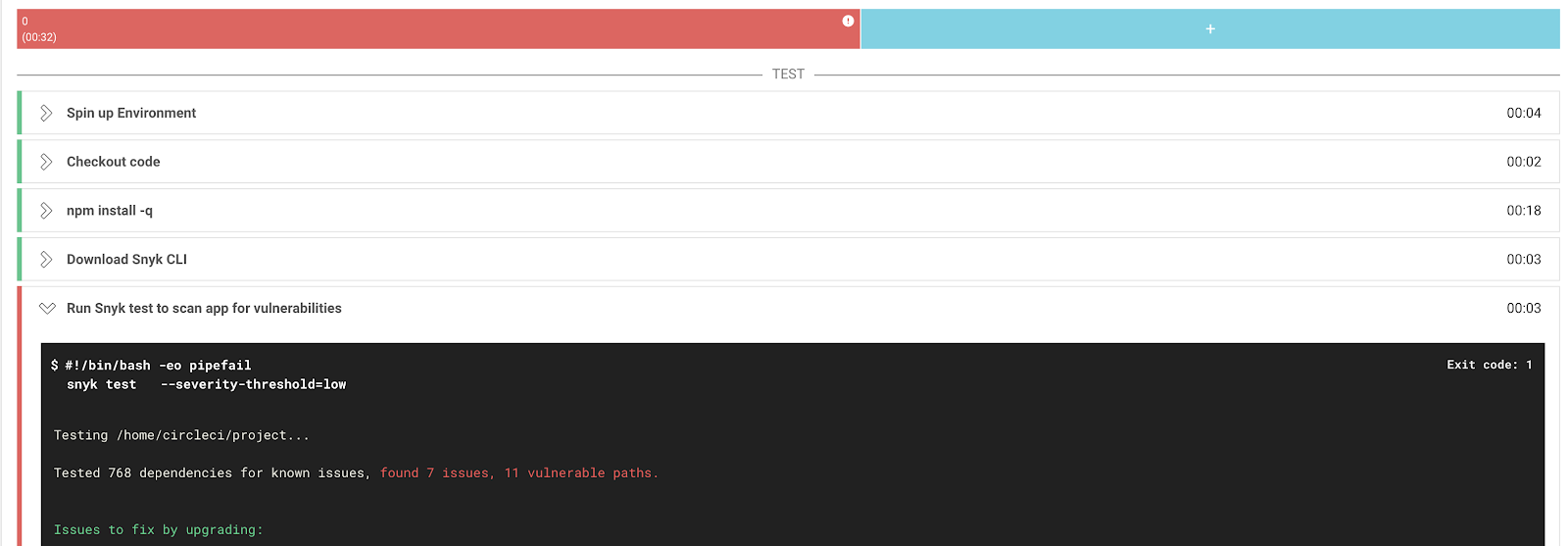
If you read my previous blogs on integrating application testing and detecting vulnerable dependencies, you know I’m a big fan of embedding such tests in your Continuous Integration and Continuous Deployment (CI/CD) pipeline. This provides instant feedback to your development team and minimises the window between discovering and fixing a vulnerability. If done right, the weakness (a secret in the code repository in this case) will not even reach the production environment, as it will be caught before the code is committed. An example is on the screenshot at the top of the page.
For this reason (and a few others), the tool that I particularly like is detect-secrets, developed in Python and kindly open-sourced by Yelp. They describe the reasons for building it and explain the architecture in their blog. It’s lightweight, language agnostic and integrates well in the development workflow. It relies on pre-commit hooks and will not scan the whole repository – only the chunk of code you are committing.
Yelp’s detect-secrets, however, has its limitations. It needs to be installed locally by engineers which might be tricky with different operating systems. If you do want to use it but don’t want to be restricted by local installation, it can also run out of a container, which can be quite handy.
I bet you already know that you should set up CloudTrail in your AWS accounts, if you haven’t already. This service captures all the API activity taking place in your AWS account and stores it in an S3 bucket for that account by default. This means you would have to configure the logging and storage permissions for every AWS account your company has. If you are tasked with securing your cloud infrastructure, you will first need to establish how many accounts your organisation owns and how CloudTrail is configured for them. Additionally, you would want to have access to S3 buckets storing these logs in every account to be able to analyse them.
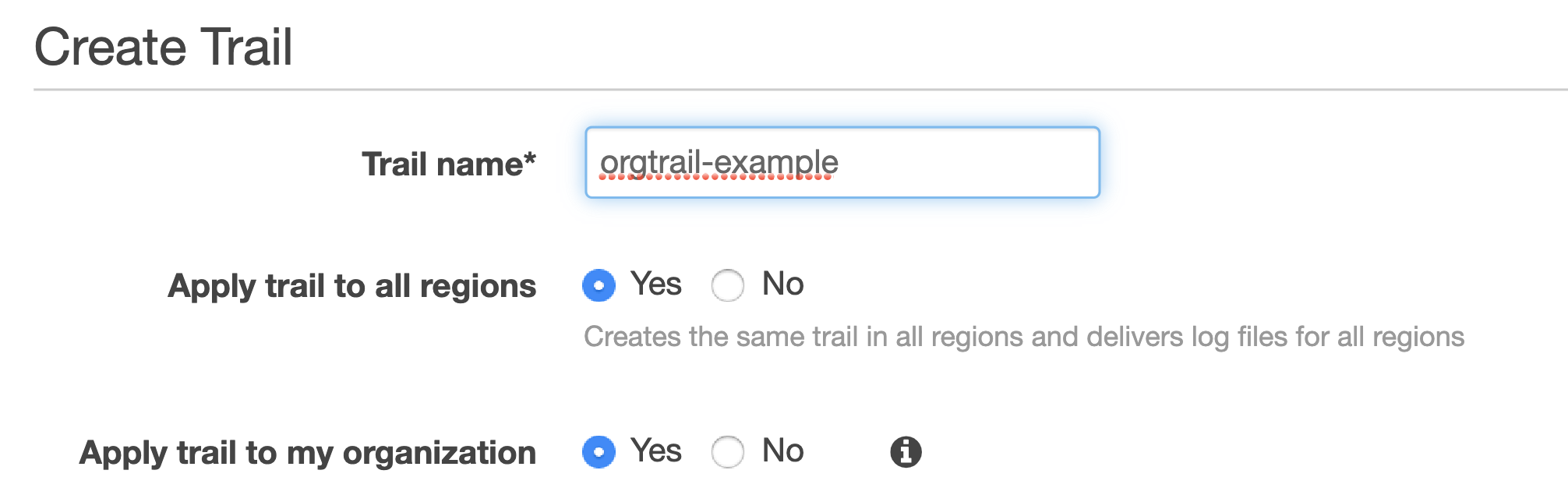
If this doesn’t sound complicated already, think of a potential error in permissions where logs can be deleted by an account administrator. Or situations where new accounts are created without your awareness and therefore not part of the overall logging pipeline. Luckily, these scenarios can be avoided if you are using the Organization Trail.
Your accounts have to be part of the same AWS Organization, of course. You would also need to have a separate account for security operations. Hopefully, this has been done already. If not, feel free to refer to my previous blogs on inventorying your assets and IAM fundamentals for further guidance on setting it up.
Establishing an Organization Trail not only allows you to collect, store and analyse logs centrally, it also ensures all new accounts created will have CloudTrail enabled and configured by default (and it cannot be turned off by child accounts).
Switch on Insights while you’re at it. This will simply the analysis down the line, alerting unusual API activity. Logging data events (for both S3 and Lambda) and integrating with CloudWatch Logs is also a good idea.
Where can all these logs be stored? The best destination (before archiving) is the S3 bucket in your account used for security operations, so that’s where it should be created.
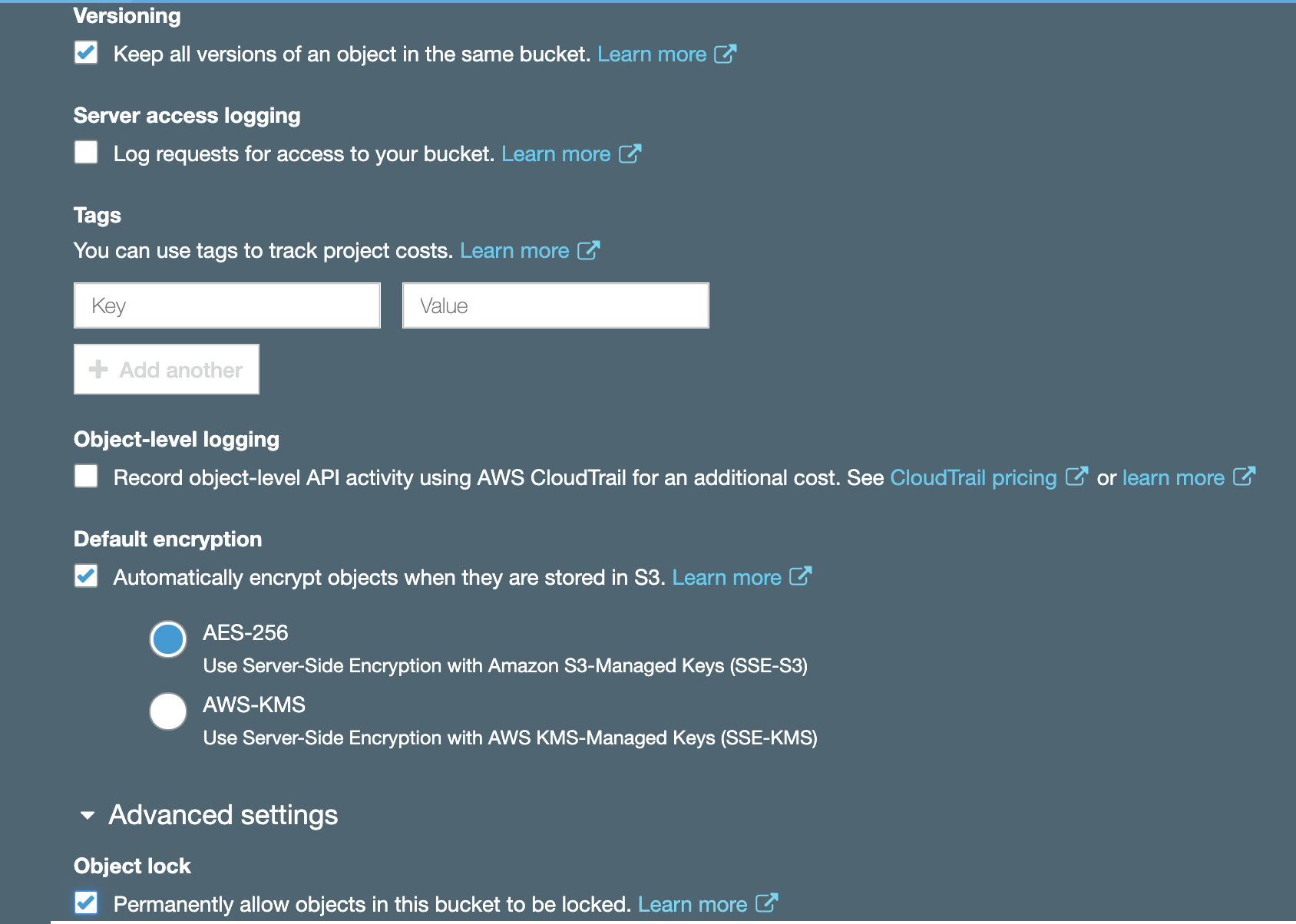
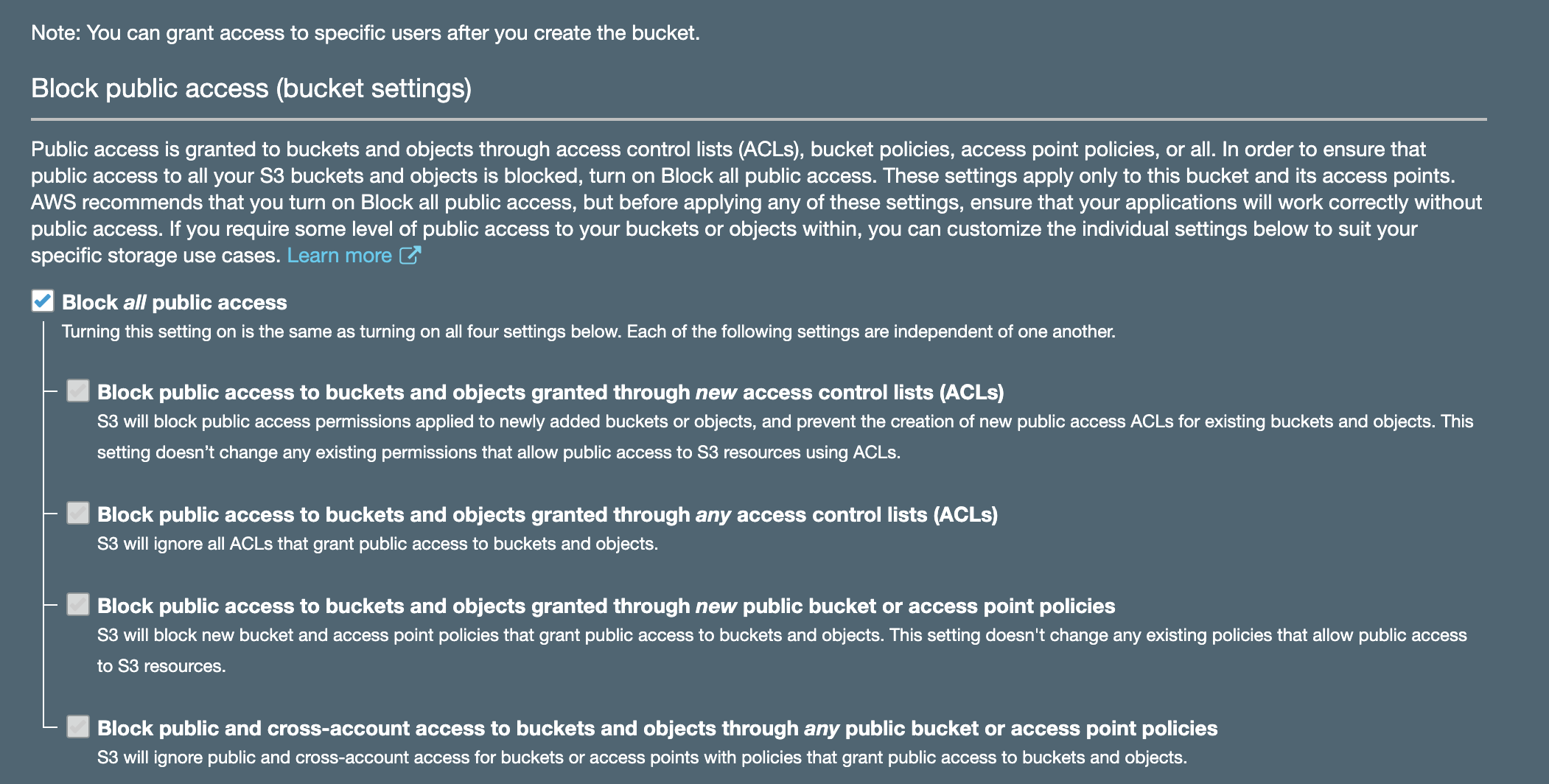
Enabling encryption and Object Lock is always a good idea. While encryption will help with confidentiality of your log data, Object Lock will ensure redundancy and prevent objects from accidental deletion. It requires versioning to be enabled and is best configured on bucket creation. Don’t forget to block public access!
You must then use your organisational root account to set up Organization Trail, selecting the bucket you created in your operational security account as a destination (rather than creating a new bucket in your master account).
For this to work, you will need to set up appropriate permissions on that bucket. It is also advisable to set up access for child accounts to be able to read their own logs.
If you had other trails in your accounts previously, feel free to turn them off to avoid unnecessary duplication and save money. It’s best to give it a day for these trails to run in parallel though to ensure nothing is lost in transition. Keep your old S3 buckets used for collection in your accounts previously; you will need these logs too. You can configure lifecycle policies and perhaps transfer them to Glacier to save on storage costs later.
And that’s how you set up CloudTrail for centralised collection, storage and analysis.
Let’s build on my previous blog on inventorying your AWS assets. I described how to use CloudMapper‘s collect command to gather metadata about your AWS accounts and report on resources used and potential security issues.
This open source tool can do more than that and it’s functionality is being continuously updated. Once the data on the accounts in scope is downloaded, various operations can be performed on it locally without the need to continuously query the accounts.
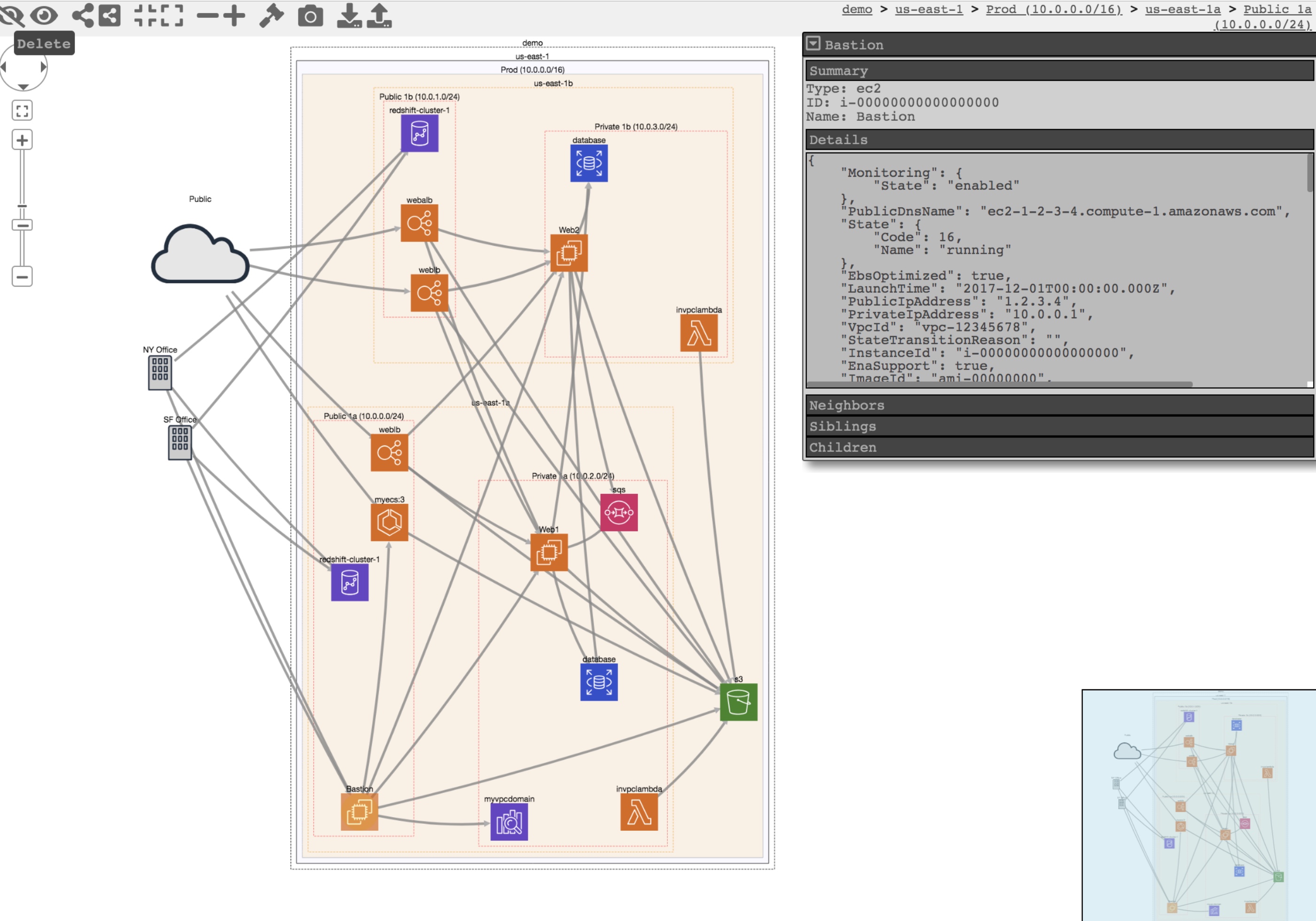
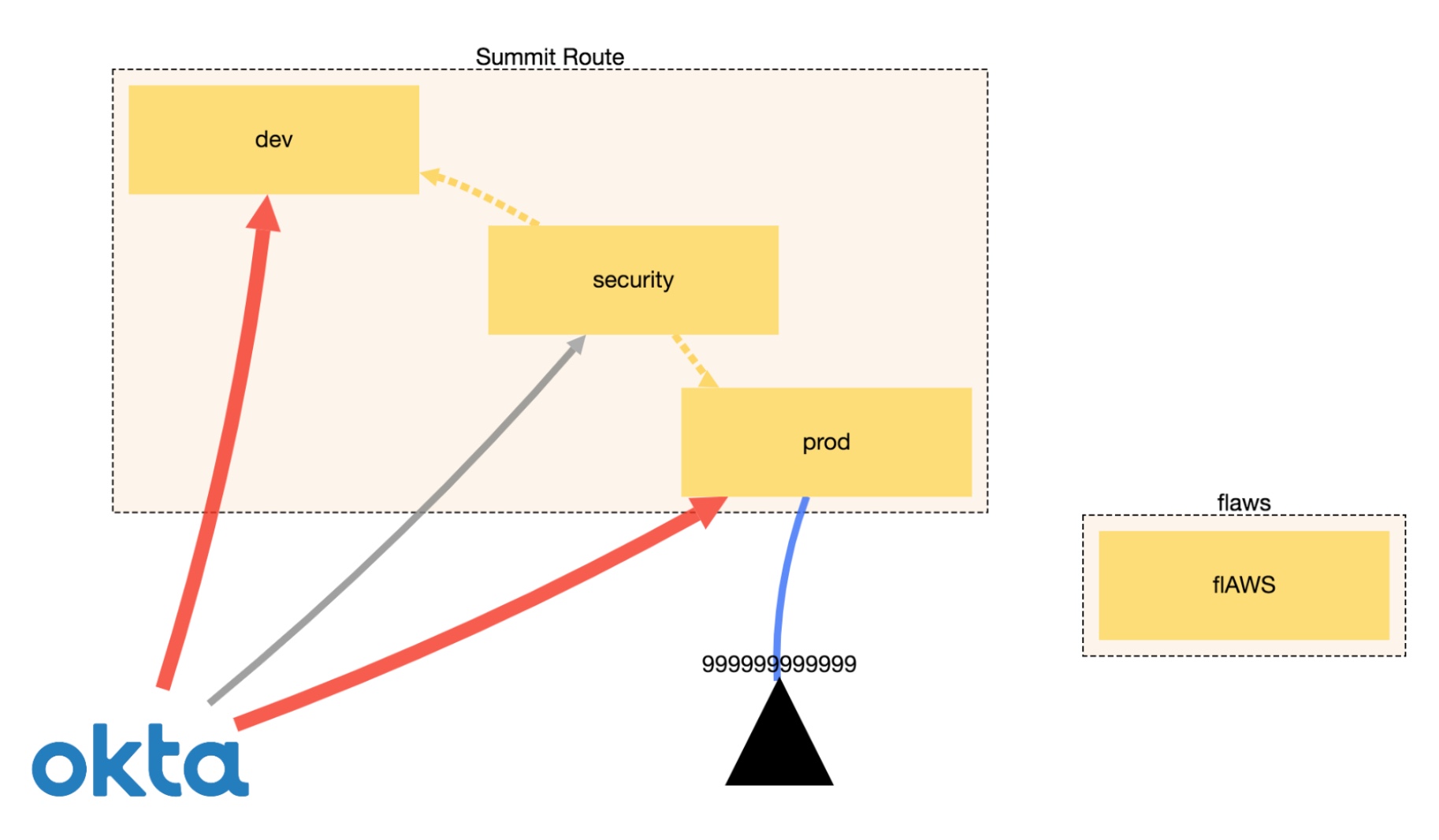
One of interesting use cases is to visualise your AWS environment in the browser. An example based on the test data of such a visualisation is at the top of this blog. You can apply various filters to reduce complexity which can be especially useful for larger environments.
Another piece of CloudMapper’s functionality is the ability to display trust relationships between accounts using the weboftrust command. Below is an example from Scott’s guidance on the use of this command. It demonstrates the connections between accounts, including external vendors.
I’m not going co cover all the commands here and suggest checking the official GitHub page for the latest list. I also recommend running CloudMapper regularly, especially in environments that constantly evolve.
An approach of that conducts regular audits. saving reports and integrating with Slack for security alerts is described here.
In the previous blog, I wrote about how you as a security specialist can succeed in the world of agile development, where the requirements are less clear, environment more fluid and change is celebrated not resisted.
Adjusting your mindset and embracing the fact that there will be plenty of unknowns is the first step in adopting agile security practices. You can still influence the direction of the product development to make it more resilient, safe and secure by working with the Product Owner and contributing your requirements to the product backlog.
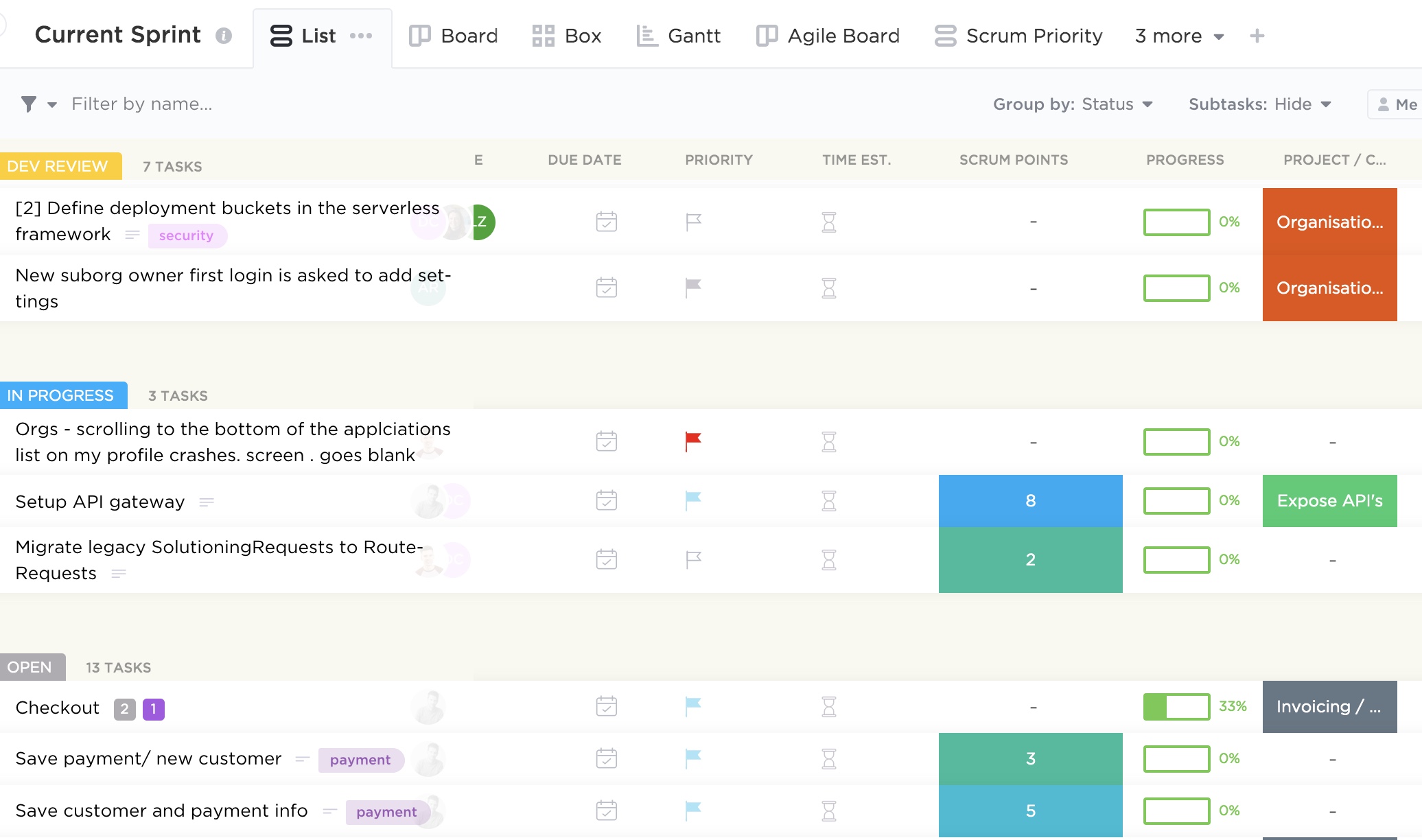
Simply put, product backlog is a list of desired functionality, bug fixes and other requirements needed to deliver a viable product. There are plethora of tools out there to help manage dependencies and prioritisation to make the product owner’s job easier. The image at the top of this post is an example of one of such tools and you can see some example requirements there.
As a security specialist, you can communicate your needs in a form of user stories or help contribute to existing ones, detailing security considerations. For example, ”Customer personal data should be stored securely” or “Secure communication channels should be used when transmitting sensitive information”. Below are a couple more examples from different categories.
When writing security user stories, you should try and elaborate as much as possible on the problem you are trying to solve, what value it will provide if solved and the acceptance criteria. Each story will then have points assigned which signifies how much effort a particular functionality will require. The process of arriving to the final number is quite democratic and usually involves playing planning (sometimes also called Scrum) poker in which every developer will estimate how long each story is going to take with some discussion and eventual consensus. You can do it with an app as on the image below, or the old school way with a deck of cards.
You don’t have to use the above number pattern, and opt-in instead for the Fibonacci sequence or T-shirt sizes.
It’s important that the security team is involved in sprint planning to contribute to the estimates and help the product owner with prioritisation. Other Scrum meetings, like backlog refinement and daily stand-ups are also worthwhile to attend to be able clarify your requirements (including value, risk, due dates and dependencies) and help remove security related impediments.
A culture of collaboration between teams is essential for the DevSecOps approach to be effective. Treating security as not something to workaround but as a value adding product feature is the mindset product and engineering teams should adopt. However, it’s up to security specialists to recognise the wider context in which they operate and accept the fact that security is just one of the requirements the team needs to consider. If the business can’t generate revenue because crucial features that customers demand are missing, it’s little consolation that security vulnerabilities have been addressed. After all, it’s great to have a secure product, but less so when nobody uses it.
Outline security requirements at the beginning of the project, review the design to check if the requirements have been incorporated and perform security testing before go-live. If this sounds familiar, it should. Many companies manage their projects using the waterfall method, where predefined ‘gates’ have to be cleared before the initiative can move forward. The decision can be made at certain checkpoints to not proceed further, accepting the sunk costs if benefits now seem unlikely to be realised.
This approach works really well in structured environments with clear objectives and limited uncertainty and I saw great things being delivered using this method in my career. There are many positives from the security point of view too: the security team gets involved as they would normally have to provide their sign-off at certain stage gates, so it’s in the project manager’s interest to engage them early to avoid delays down the line. Additionally, the security team’s output and methodology are often well defined, so there are no surprises from both sides and it’s easier to scale.
If overall requirements are less clear, however, or you are constantly iterating to learn more about your stakeholder’s needs to progressively elaborate on the requirements, to validate and perhaps even pivot from the initial hypothesis, more agile project management methodologies are more suitable.
Embedding security in the agile development is less established and there is more than one way of doing it.
When discussing security in startups and other companies adopting agile approaches, I see a lot of focus on automating security tests and educating developers on secure software development. Although these initiatives have their merits, it’s not the whole story.
Security professionals need to have the bigger picture in mind and work with product teams to not only prevent vulnerabilities in code, but influence the overall product strategy, striving towards security and privacy by design.
Adding security features and reviewing and refining existing requirements to make the product more secure is a step in the right direction. To do this effectively, developing a relationship with the development and product teams is paramount. The product owner especially should be your best friend, as you often have to persuade them to include your security requirements and user stories in sprints. Remember, as a security specialist, you are only one of the stakeholders they have to manage and there might be a lot of competing requirements. Besides, there is a limited amount of functionality the development can deliver each sprint, so articulating the value and importance of your suggestions becomes an essential skill.
Few people notice security until it’s missing, then the only thing you can notice is the absence of it. We see this time and time again when organisations of various sizes are grappling with data breaches and security incidents. It’s your job to articulate the importance of prioritising security requirements early in the project to mitigate the potential rework and negative impact in the future.
One way of doing this is by refining existing user stories by adding security elements to them, creating dedicated security stories, or just adding security requirements to the product backlog. Although the specifics will depend on your organisation’s way of working, I will discuss some examples in my next blog.
We learnt how to detect vulnerable packages in your projects using Snyk in the previous blog. Here, in the true DevSecOps fashion, I would like outline how to integrate this tool in your CI/CD pipeline.
Although the approach described in the previous blog has its merits, it lacks proactivity, which means you might end up introducing outdated packages in your codebase. To address this limitation, I’m going to describe how to make Snyk checks part of your deployment workflow. I’ll be using CircleCI here as an example, but the principles can be applied using any CI tool.
A step-by-step guidance on configuring the integration is available on both the Snyk and CircleCI websites. In the nutshell, it’s just about adding the Snyk Orb and API to CircleCI.
After the initial set-up, an additional test will be added to your CircleCI workflow.
If vulnerabilities are identified, you can set CircleCI to either fail the build to prevent outdated libraries to be introduced or let the build complete and flag.
Both methods have their pros and cons and will depend on the nature of your environment and risk appetite. It’s tempting to force the build fail to prevent more vulnerable dependencies being introduced but I suggest doing so only after checking with your developers and remediating existing issues in your repositories using the method described in the previous blog.
Snyk’s free version allows you only a limited number of scans per month, so you need to also weigh costs agains benefits when deploying this tool in your development, staging and production environments.
This approach will allow you to automate security tests in a developer-friendly fashion and hopefully bring development and security teams closer together, so the DevSecOps can be practiced.
We rely on open source libraries when we write code because it saves a lot of time (modern applications rely on hundreds of them), but these dependencies can also introduce vulnerabilities that are tricky to manage and easy to exploit by attackers.
One way of addressing this challenge is to check the open source packages you use for known vulnerabilities.
In this blog I would like to discuss how to do this using an open source tool called Snyk.
The first thing you want to do after creating an account is to integrate Snyk with your development environment. It supports a fair amount of systems, but here I would like to talk about GitHub as an example. The process of getting the rest of the integrations are pretty similar.
Snyk’s browser version has an intuitive interface and all you need to do is go to the Integrations tab, select GitHub and follow the instructions.
After granting the necessary permissions and selecting the code repositories you want tested (don’t forget the private ones too), they will be immediately scanned.
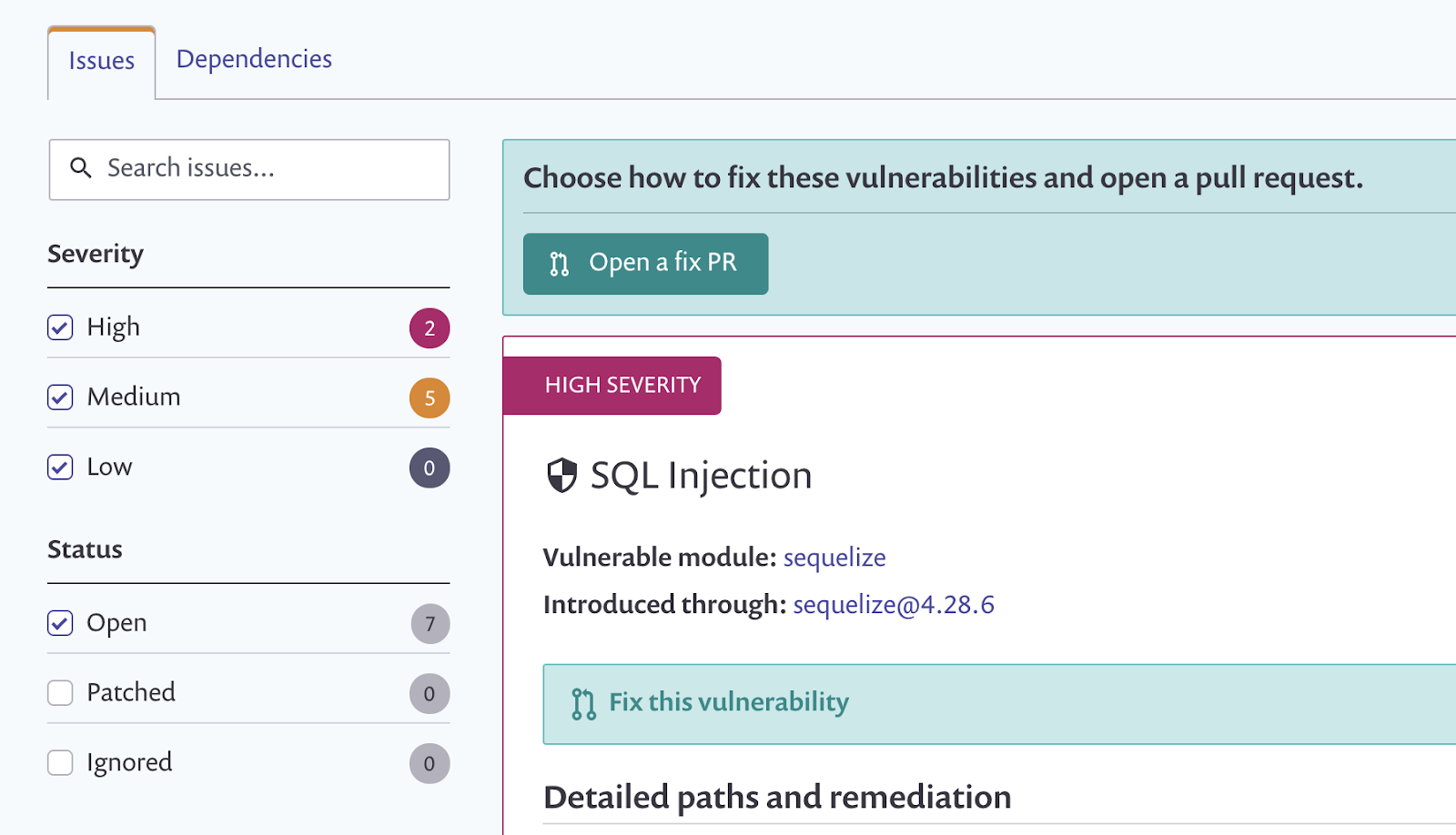
You will be able to see the results in the Projects tab with issues conveniently ordered by severity so you can easily prioritise what to tackle first. You can also see the dependency tree there which can be quite handy.
A detailed description of the vulnerability and some recommendations on how to remediate it are also provided.
Most vulnerabilities can be fixed through either an upgrade or a patch and that’s what you should really do, or ask someone (perhaps by creating a ticket) if you don’t own the codebase. Make sure you test it first though as you don’t want the update to break your application.
Some fancy reporting (and checking license compliance) is only available in the paid plan but the basic version does a decent job too.
You can set up periodic tests with desired frequency (daily or weekly) which technically counts as continuous monitoring but it’s only the second best option compared to performing tests in your deployment pipeline. Integrating Snyk in your CI/CD workflow allows to prevent issues in your code before it even gets deployed. This is especially useful in organisations where code gets deployed multiple times a day with new (potentially vulnerable) libraries being introduced. And that’s something we are going to discuss in my next blog.